
吴恩达团队NLP C3_W4_Assignment
任务:判断两个问题是否重复
Part1:数据生成器
1 | def data_generator(Q1, Q2, batch_size, pad=1, shuffle=True): |
test:
1 | batch_size = 2 |
1 | First questions : |
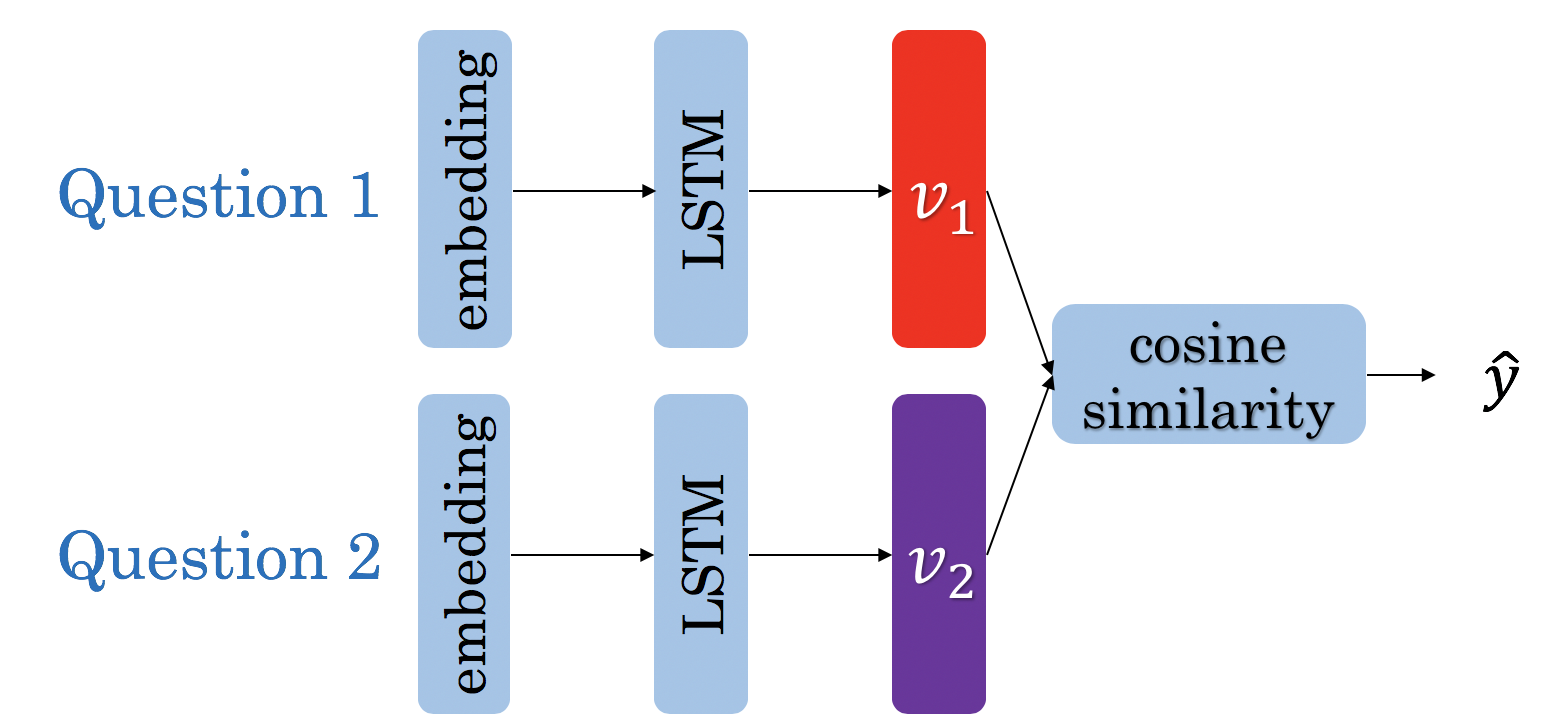
Part2:定义Siamese模型
神经网络结构如下:
当我们计算损失函数时,我们使用triplet loss(三元组损失),如下图所示:
- 锚示例与正面示例的余弦相似度接近1
- 锚示例与负面示例的余弦相似度接近-1

我们需要优化以下公式:
从下图中我们可以看到:
- 当$cos(A,P) = 1, cos(A,N) = -1$时,成本小于0
- 反之,则成本大于0

由于我们不想有负成本,所以我们可以用以下公式:
- 我们使用了α来控制$cos(A,P$)和$cos(A,N)$的距离
通过简化,我们试图最大化以下内容:
1 | def Siamese(vocab_size=len(vocab), d_model=128, mode='train'): |
2.1 Hard Negative Mining
我们可以从下图看到,v1,v2只有对应行是重复的(图中数据有误),所以我们将矩阵相乘。
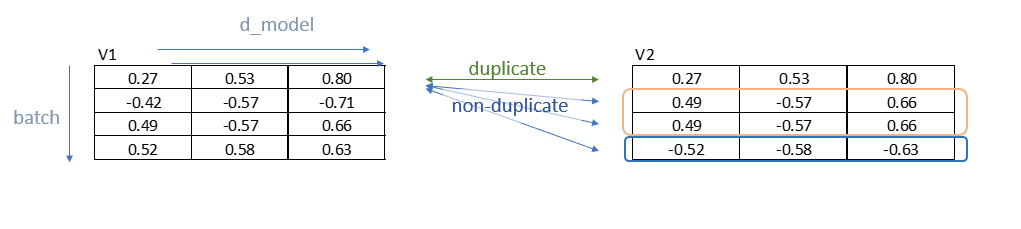
相乘后,矩阵的对角线便为重复问题的分数,其余为锚点与反面例子的余弦值

损失函数如下:
1 | def TripletLossFn(v1, v2, margin=0.25): |
2.2 编写没有可训练变量的损失层
1 | from functools import partial |
Part3:训练模型
1 | lr_schedule = trax.lr.warmup_and_rsqrt_decay(400, 0.01) |
Part4:评估模型
4.1 导入之前训练的模型
1 | model = Siamese() |
4.2 分类测试准确率
1 | def classify(test_Q1, test_Q2, y, threshold, model, vocab, data_generator=data_generator, batch_size=64): |
Part5:测试自己的问题
1 | def predict(question1, question2, threshold, model, vocab, data_generator=data_generator, verbose=False): |
test:
1 | question1 = "When will I see you?" |
1 | Q1 = [[585 76 4 46 53 21 1 1]] |