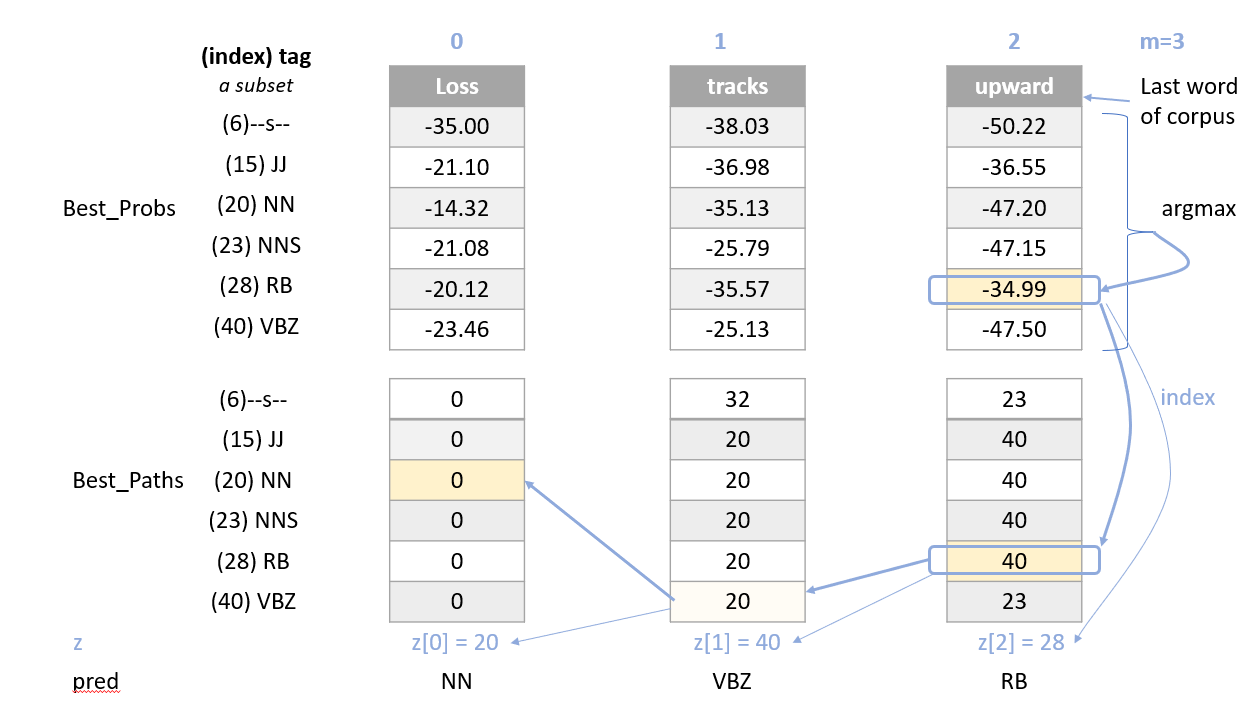
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| def initialize(states, tag_counts, A, B, corpus, vocab):
'''
Input:
states: a list of all possible parts-of-speech
tag_counts: a dictionary mapping each tag to its respective count
A: Transition Matrix of dimension (num_tags, num_tags)
B: Emission Matrix of dimension (num_tags, len(vocab))
corpus: a sequence of words whose POS is to be identified in a list
vocab: a dictionary where keys are words in vocabulary and value is an index
Output:
best_probs: matrix of dimension (num_tags, len(corpus)) of floats
best_paths: matrix of dimension (num_tags, len(corpus)) of integers
'''
num_tags = len(tag_counts)
best_probs = np.zeros((num_tags, len(corpus)))
best_paths = np.zeros((num_tags, len(corpus)), dtype=int)
s_idx = states.index("--s--")
for i in range(num_tags):
if A[s_idx, i] == 0:
best_probs[i,0] = float('-inf')
else:
best_probs[i,0] = math.log(A[s_idx, i]) + math.log(B[i, vocab[corpus[0]]])
return best_probs, best_paths
|