
题目简介:
在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
示例 1:
1 | 输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery" |
示例 2:
1 | 输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs" |
思路
- 最简单的便是暴力搜索了,首先我们将词根字典中的单词根据长度由小到大进行排序。在判断每个单词时,我们根据排好序后的字典,从前往后进行搜索,观察是否存在可以替换的词根。
第二种方法便是使用字典树,首先来了解一下什么是字典树:
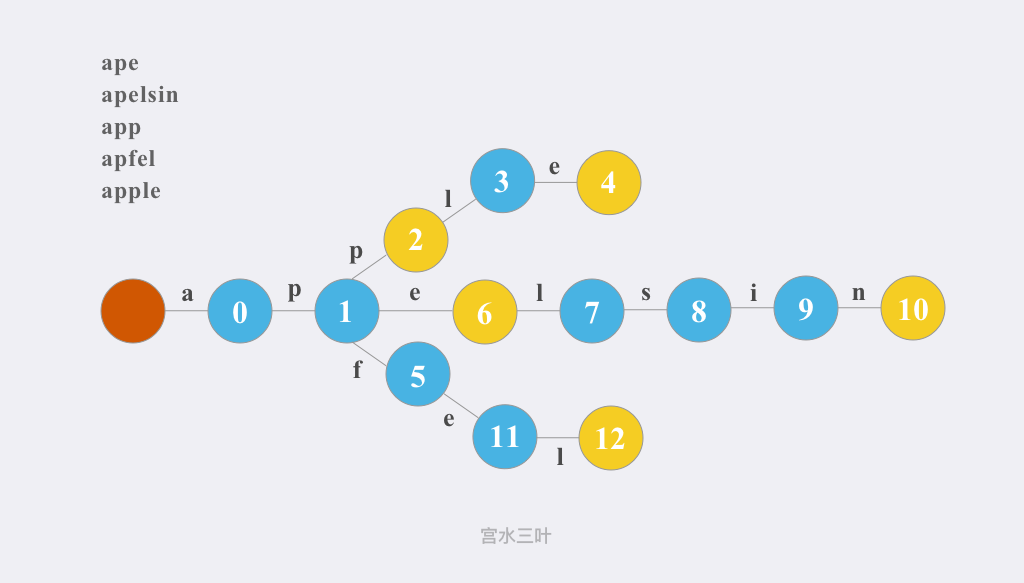
如上图所示,字典树的边代表了一个个字符,这样我们在搜索树的时候就可以知道某个单词的前缀是否存在于这棵树中了,如果存在,便说明是可以被替换了。那么,为了来判断当前结点是否为一个单词的结尾,我们可以加入$bool$类型的变量来存储该信息(也就是图中的黄色结点)。
构建完字典树后,我们查找句子中的每一个单词时,都可以通过字典树线性的查找前缀,这样就缩短了时间复杂度,使得时间复杂度为$O(d + s)$,其中 d 是 $dictionary$ 的字符数,s 是 $sentence$ 的字符数。构建字典树消耗 $O(d)$ 时间,每个单词搜索前缀均消耗线性时间。
代码如下:
暴力搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53bool cmp(string a, string b){
return a.length() < b.length();
}
class Solution {
public:
string find(string &word, vector<string>& dictionary){
for(int i = 0; i < dictionary.size(); i++){
if(word.substr(0, dictionary[i].length()) == dictionary[i])
return dictionary[i];
}
return "-1";
}
string replaceWords(vector<string>& dictionary, string sentence) {
sort(dictionary.begin(), dictionary.end(), cmp);
int idx = 0;
string res = "";
while(idx < sentence.length()){
if(idx != 0)
res += " ";
string now_word = sentence.substr(idx, sentence.find(" ", idx) - idx);
string res_now = find(now_word, dictionary);
if(res_now != "-1"){
res += res_now;
}
else
res += now_word;
if(sentence.find(" ", idx) == sentence.npos)
break;
else
idx = sentence.find(" ", idx) + 1;
}
return res;
}
};字典树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90struct Trie{
bool isend;
Trie* next[26];
};
class Solution {
public:
void insert(Trie* node, string& word){
for(auto ch : word){ //遍历每个字符
if(node -> next[ch - 'a'] == nullptr) //不存在该节点
node -> next[ch - 'a'] = new Trie(); //创建该节点
node = node -> next[ch - 'a'];
}
node -> isend = true;
}
string find(Trie* root, string& word){ //查找
string res;
for(auto ch : word){
if(root -> next[ch - 'a'] == nullptr)
return word;
root = root -> next[ch - 'a'];
res.push_back(ch);
if(root -> isend) //提前找到
return res;
}
if(root -> isend) //到达结尾,且为词根
return res;
else
return word;
}
vector<string> split(string &str, char ch) { //切割函数
int pos = 0;
int start = 0;
vector<string> ret;
while (pos < str.size()) {
while (pos < str.size() && str[pos] == ch) {
pos++;
}
start = pos;
while (pos < str.size() && str[pos] != ch) {
pos++;
}
if (start < str.size()) {
ret.emplace_back(str.substr(start, pos - start));
}
}
return ret;
}
string replaceWords(vector<string>& dictionary, string sentence) {
Trie* root = new Trie();
for(auto word : dictionary){
insert(root, word);
}
vector<string> words = split(sentence, ' ');
string res = "";
int flag_res = 0;
for(auto word : words){
if(flag_res != 0)
res += " ";
res += find(root, word);
flag_res = 1;
}
return res;
}
};