吴恩达团队NLP C2_W4_Assignment
任务:计算单词嵌入并用于情感分析
Part1:The Continuous bag of words model(CBOW)
在这个模型下,我们给出上下文的单词,并尝试判断中间词。
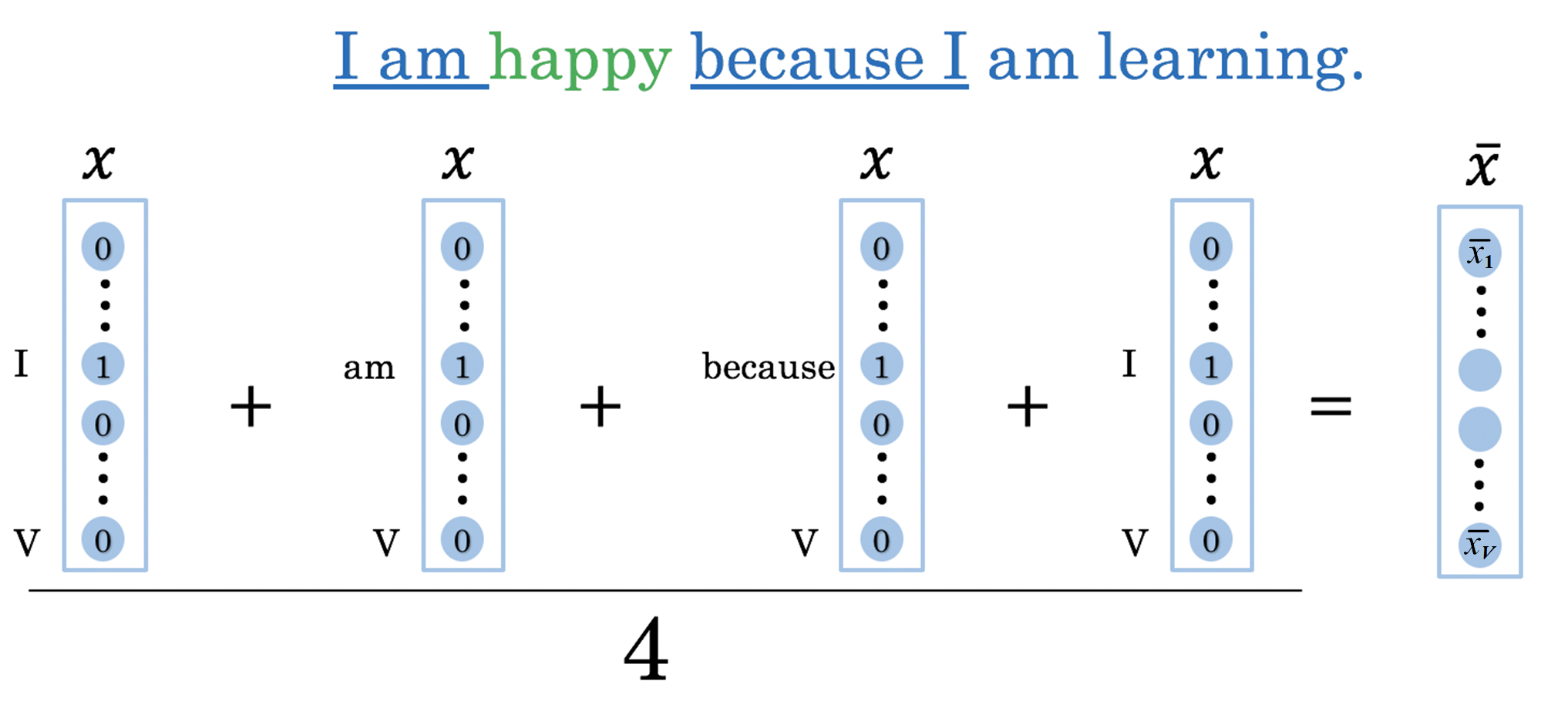
如有个字符串为:I am happy because I am learning
我们设C = 2 ,当我们要预测happy时,则:
- 𝐶 words before:
[I, am] - 𝐶 words after:
[because, I]
模型结构图如下:

其中$\bar x$为:
公式如下:
1.1 初始化模型
我们将初始化W1, W2矩阵和b1, b2向量:
- W1:N * V
- W2:V * N
- b1:N * 1
- b2:V * 1
其中V为单词数,N为单词向量维数。
1 | def initialize_model(N,V, random_seed=1): |
1.2 softmax
1 | def softmax(z): |
1.3 前向传播
通过以下三个公式实现正向传播:
1 | def forward_prop(x, W1, W2, b1, b2): |
1.4 反向传播

1 | def back_prop(x, yhat, y, h, W1, W2, b1, b2, batch_size): |
1.5 梯度下降
1 | def gradient_descent(data, word2Ind, N, V, num_iters, alpha=0.03): |
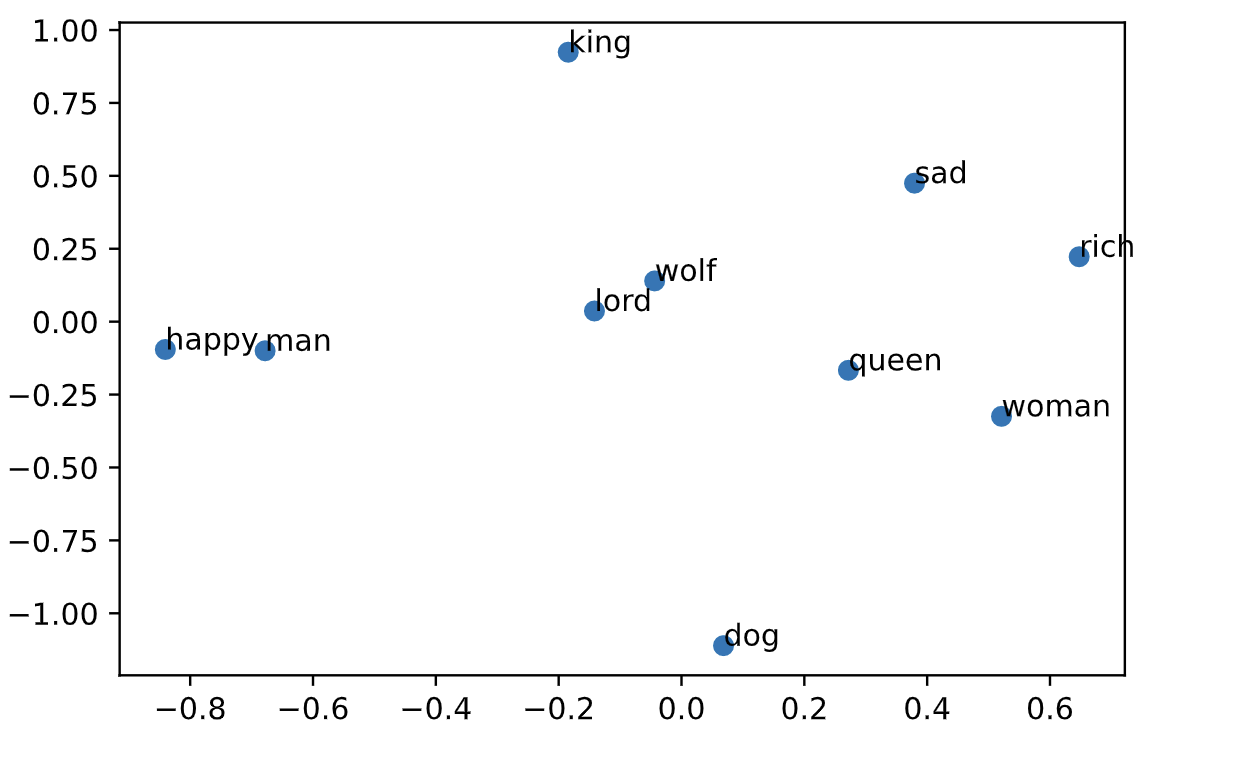
1.6 可视化单词向量(由于不是在官网上编程,所以结果图可能会有误差)
1 | from matplotlib import pyplot |
1 | (10, 50) [2744, 3949, 2960, 3022, 5672, 1452, 5671, 4189, 2315, 4276] |
1 | result= compute_pca(X, 2) |

1 | result= compute_pca(X, 4) |