
吴恩达深度学习 C1_W4_Assignment
任务1:一步一步构建深层神经网络
Part0:库的准备
1 | import numpy as np |
步骤图:
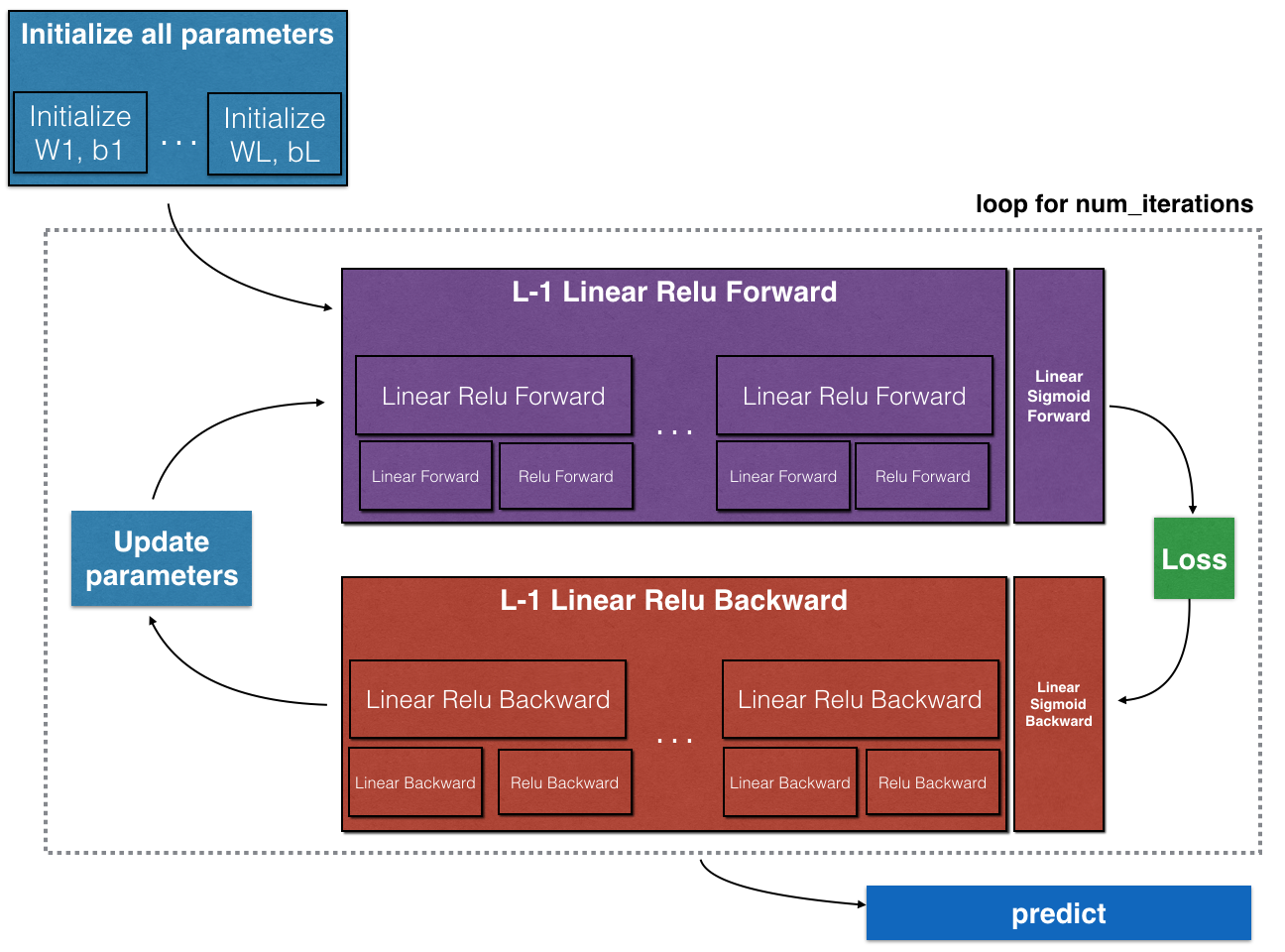
Part1:初始化
Exercise1:创建并初始化2层神经网络参数
模型结构:LINEAR -> RELU -> LINEAR -> SIGMOID
1 | def initialize_parameters(n_x, n_h, n_y): |
Exercise2:实现L层神经网络的初始化
1 | def initialize_parameters_deep(layer_dims): |
Part2:前向传播模块
接下来将完成三个函数:
- LINEAR
- LINEAR -> ACTIVATION where ACTIVATION will be either ReLU or Sigmoid.
- [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID (whole model)
Exercise3:完成Linear的前向传播
1 | def linear_forward(A, W, b): |
Exercise4:完成LINEAR->ACTIVATION的前向传播
其中g() 为sigmoid或relu
1 | def linear_activation_forward(A_prev, W, b, activation): |
Exercise5:实现L层模型的前向传播
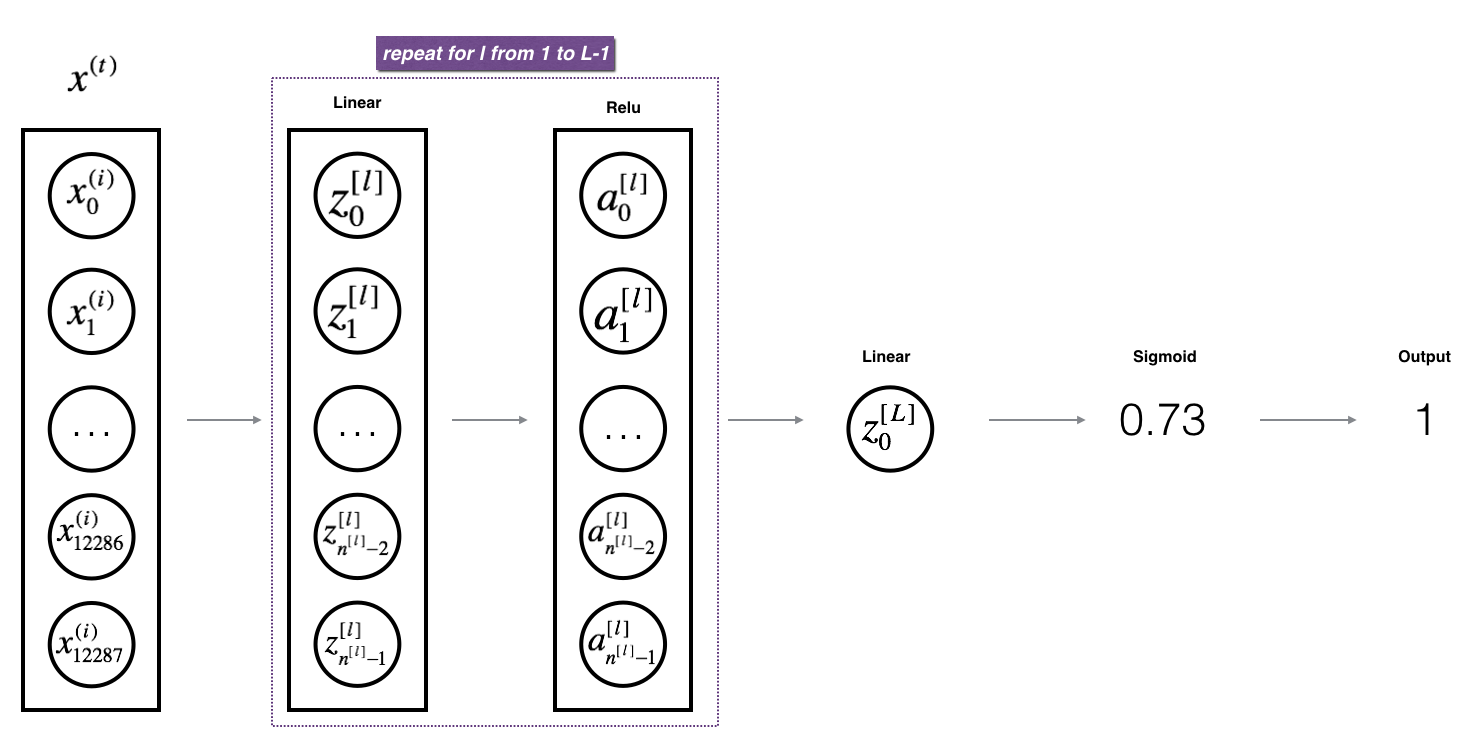
1 | def L_model_forward(X, parameters): |
Part3:成本函数
Exercise6:计算成本函数
1 | # GRADED FUNCTION: compute_cost |
Part4:反向传播模块

和前向传播一样,我们需要逐步完成三个函数:
- LINEAR backward
- LINEAR -> ACTIVATION backward where ACTIVATION computes the derivative of either the ReLU or sigmoid activation
- [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID backward (whole model)
Exercise7:Linear backward

1 | def linear_backward(dZ, cache): |
Exercise8:Linear-Activation backward
1 | def linear_activation_backward(dA, cache, activation): |
Exercise9:L-Model Backward
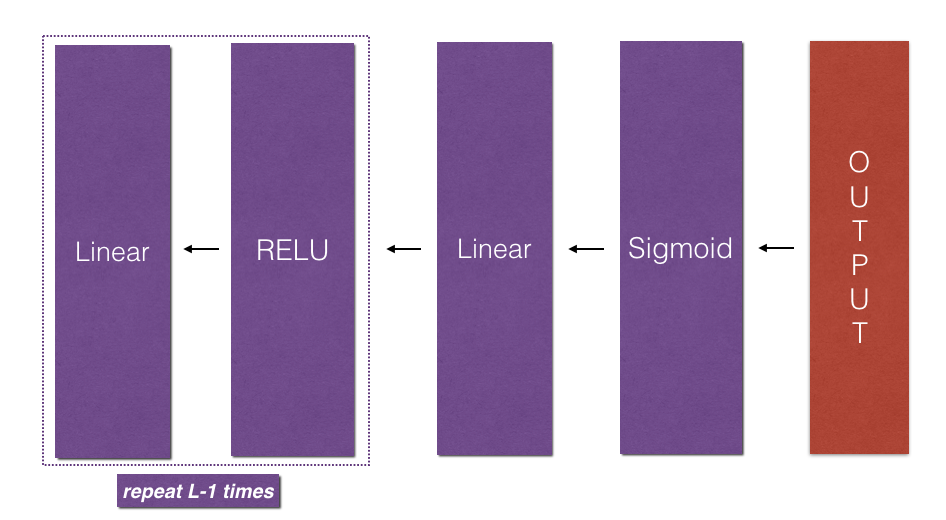
1 | def L_model_backward(AL, Y, caches): |
Exercise10:更新参数
1 | def update_parameters(parameters, grads, learning_rate): |
任务2:深度神经网络在图像分类中的应用
Part0:库的准备
1 | import time |
Part1:数据准备
我们将使用与实验2相同的数据集,并来观察此次的模型是否能提高识别准确率
我们来观察一下测试集与训练集的情况
1 | m_train = train_x_orig.shape[0] |
1 | Number of training examples: 209 |
我们将图像向量化:

1 | # Reshape the training and test examples |
1 | train_x's shape: (12288, 209) # 12288 = 64 * 64 * 3 |
Part2:模型结构
我们将构建两种不同的模型:
- 2层神经网络
- L层深度神经网络
Exercise11:2层神经网络
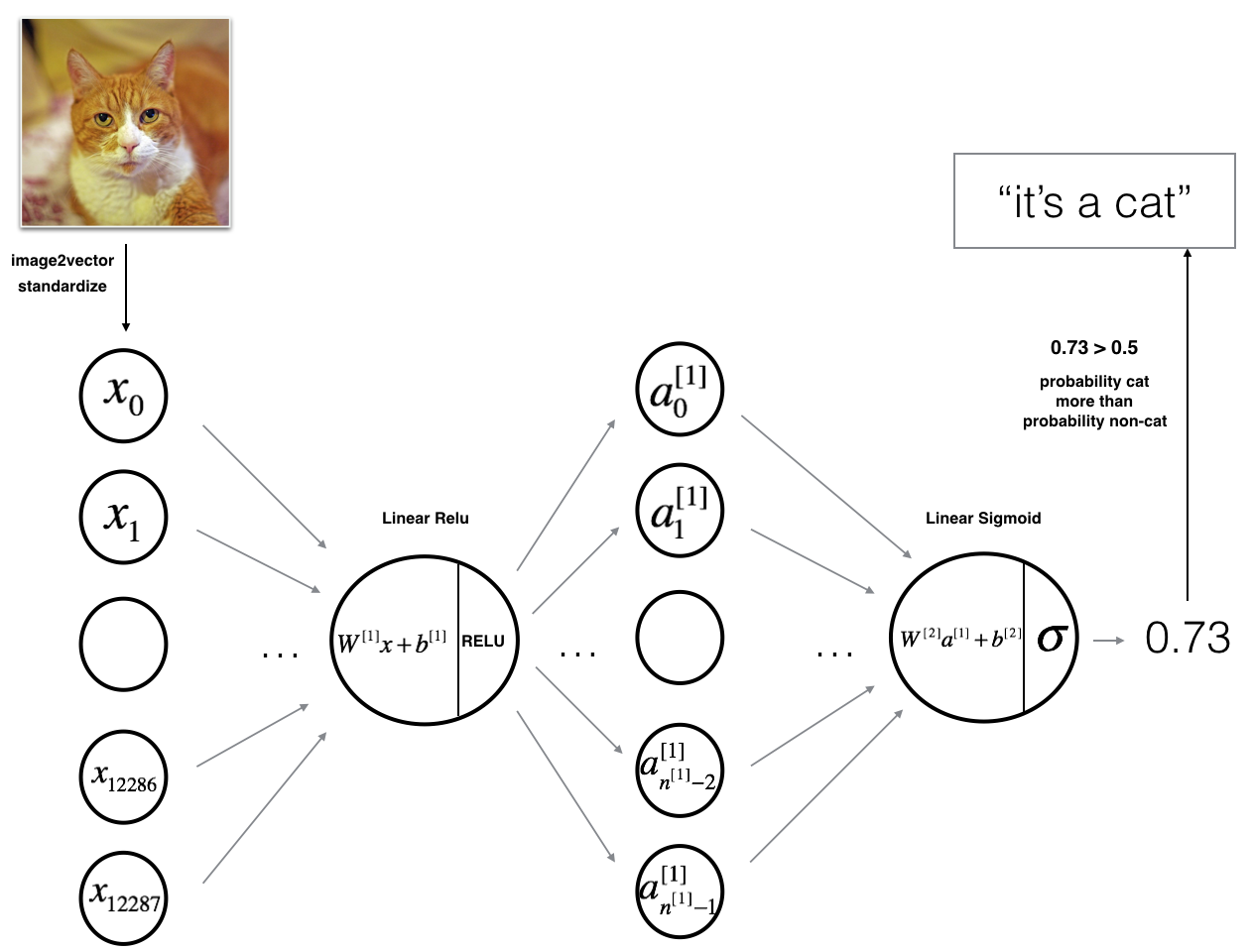
1 | n_x = 12288 # num_px * num_px * 3 (64 * 64 * 3) |
1 | def two_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False): |
测试:
1 | parameters = two_layer_model(train_x, train_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True) |

通过准确率的测试,可以得到结果为72%。
Exercise12:L层神经网络
1 | layers_dims = [12288, 20, 7, 5, 1] # 5-layer model |
1 | def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):#lr was 0.009 |
测试:
1 | parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True) |

通过准确率的测试,可以得到结果为80%。由此可以得到结果,在相同的测试集上,5层神经网络比2层神经网络效果更好。
Part3:错误结果分析
1 | print_mislabeled_images(classes, test_x, test_y, pred_test) |

该模型往往表现不佳的几种图像类型包括:
- 猫的身体处于一个不寻常的位置
- 猫在相似颜色的背景下出现
- 不寻常的猫的颜色和种类
- 摄像机角度
- 画面的亮度
- 比例变化(图像中猫很大或很小)