# This should be much faster as the data is downloaded already. eval_stream_fn = trax.data.TFDS('cnn_dailymail', data_dir='data/', keys=('article', 'highlights'), train=False)
deftokenize(input_str, EOS=1): """Input str to features dict, ready for inference"""
# Use the trax.data.tokenize method. It takes streams and returns streams, # we get around it by making a 1-element stream with `iter`. inputs = next(trax.data.tokenize(iter([input_str]), vocab_dir='vocab_dir/', vocab_file='summarize32k.subword.subwords'))
# 结尾加上标记 return list(inputs) + [EOS]
defdetokenize(integers): """List of ints to str"""
s = trax.data.detokenize(integers, vocab_dir='vocab_dir/', vocab_file='summarize32k.subword.subwords')
# Special tokens SEP = 0# Padding or separator token EOS = 1# End of sentence token
# Concatenate tokenized inputs and targets using 0 as separator. defpreprocess(stream): for (article, summary) in stream: joint = np.array(list(article) + [EOS, SEP] + list(summary) + [EOS]) mask = [0] * (len(list(article)) + 2) + [1] * (len(list(summary)) + 1) # Accounting for EOS and SEP yield joint, joint, np.array(mask)
# You can combine a few data preprocessing steps into a pipeline like this. input_pipeline = trax.data.Serial( # Tokenizes trax.data.Tokenize(vocab_dir='vocab_dir/', vocab_file='summarize32k.subword.subwords'), # Uses function defined above preprocess, # Filters out examples longer than 2048 trax.data.FilterByLength(2048) )
# Apply preprocessing to data streams. train_stream = input_pipeline(train_stream_fn()) eval_stream = input_pipeline(eval_stream_fn())
assert sum((train_input - train_target)**2) == 0# They are the same in Language Model (LM).
1.5 Bucketing
我们将长度相似的句子放在一起,并提供最小的填充,如下图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13
# Buckets are defined in terms of boundaries and batch sizes. # Batch_sizes[i] determines the batch size for items with length < boundaries[i] # So below, we'll take a batch of 16 sentences of length < 128 , 8 of length < 256, # 4 of length < 512. And so on. boundaries = [128, 256, 512, 1024] batch_sizes = [16, 8, 4, 2, 1]
# Create the streams. train_batch_stream = trax.data.BucketByLength( boundaries, batch_sizes)(train_stream)
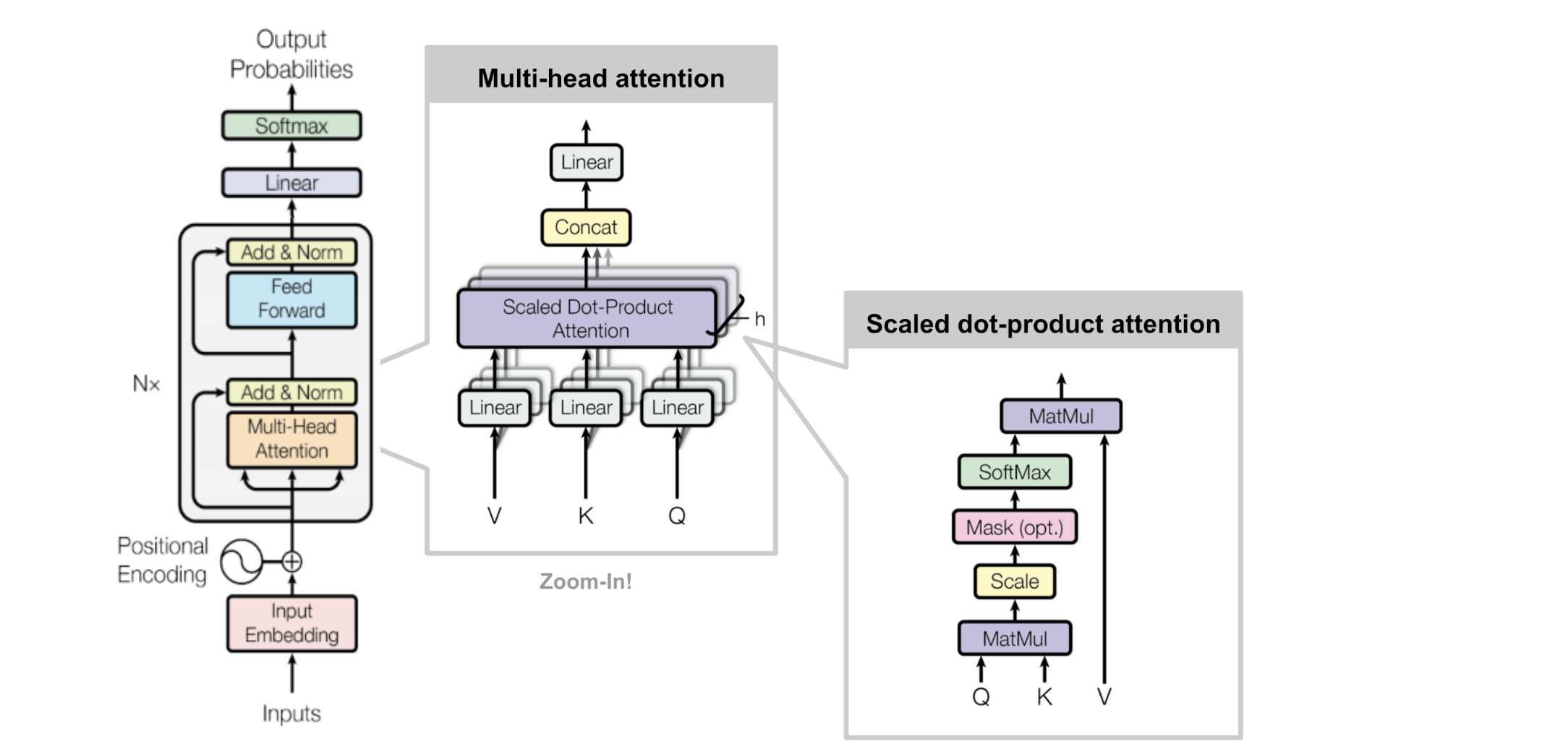
defDotProductAttention(query, key, value, mask): """Dot product self-attention. Args: query (jax.interpreters.xla.DeviceArray): array of query representations with shape (L_q by d) key (jax.interpreters.xla.DeviceArray): array of key representations with shape (L_k by d) value (jax.interpreters.xla.DeviceArray): array of value representations with shape (L_k by d) where L_v = L_k mask (jax.interpreters.xla.DeviceArray): attention-mask, gates attention with shape (L_q by L_k) Returns: jax.interpreters.xla.DeviceArray: Self-attention array for q, k, v arrays. (L_q by L_k) """
assert query.shape[-1] == key.shape[-1] == value.shape[-1], "Embedding dimensions of q, k, v aren't all the same"
# Save depth/dimension of the query embedding for scaling down the dot product depth = query.shape[-1]
defcompute_attention_heads_closure(n_heads, d_head): """ Function that simulates environment inside CausalAttention function. Args: d_head (int): dimensionality of heads. n_heads (int): number of attention heads. Returns: function: compute_attention_heads function """
defcompute_attention_heads(x): """ Compute the attention heads. Args: x (jax.interpreters.xla.DeviceArray): tensor with shape (batch_size, seqlen, n_heads X d_head). Returns: jax.interpreters.xla.DeviceArray: reshaped tensor with shape (batch_size X n_heads, seqlen, d_head). """ # Size of the x's batch dimension batch_size = x.shape[0]
defdot_product_self_attention(q, k, v): """ Masked dot product self attention. Args: q (jax.interpreters.xla.DeviceArray): queries. k (jax.interpreters.xla.DeviceArray): keys. v (jax.interpreters.xla.DeviceArray): values. Returns: jax.interpreters.xla.DeviceArray: masked dot product self attention tensor. """ # Hint: mask size should be equal to L_q. Remember that q has shape (batch_size, L_q, d) mask_size = q.shape[-2]
# Creates a matrix with ones below the diagonal and 0s above. It should have shape (1, mask_size, mask_size) # Notice that 1's and 0's get casted to True/False by setting dtype to jnp.bool_ # Use jnp.tril() - Lower triangle of an array and jnp.ones() mask = jnp.tril(jnp.ones((1, mask_size, mask_size), dtype=jnp.bool_), k=0) return DotProductAttention(q, k, v, mask)
defcompute_attention_output_closure(n_heads, d_head): """ Function that simulates environment inside CausalAttention function. Args: d_head (int): dimensionality of heads. n_heads (int): number of attention heads. Returns: function: compute_attention_output function """ defcompute_attention_output(x): """ Compute the attention output. Args: x (jax.interpreters.xla.DeviceArray): tensor with shape (batch_size X n_heads, seqlen, d_head). Returns: jax.interpreters.xla.DeviceArray: reshaped tensor with shape (batch_size, seqlen, n_heads X d_head). """ # Length of the sequence seqlen = x.shape[1]
# Reshape x using jnp.reshape() to shape (batch_size, n_heads, seqlen, d_head) x = jnp.reshape(x, (-1, n_heads, seqlen, d_head)) # -1代表缺省,系统自动调整
# Transpose x using jnp.transpose() to shape (batch_size, seqlen, n_heads, d_head) x = jnp.transpose(x, (0, 2, 1, 3)) # Reshape to allow to concatenate the heads return jnp.reshape(x, (-1, seqlen, n_heads * d_head)) return compute_attention_output
defDecoderBlock(d_model, d_ff, n_heads, dropout, mode, ff_activation): """Returns a list of layers that implements a Transformer decoder block. The input is an activation tensor. Args: d_model (int): depth of embedding. d_ff (int): depth of feed-forward layer. n_heads (int): number of attention heads. dropout (float): dropout rate (how much to drop out). mode (str): 'train' or 'eval'. ff_activation (function): the non-linearity in feed-forward layer. Returns: list: list of trax.layers.combinators.Serial that maps an activation tensor to an activation tensor. """ # Create masked multi-head attention block using CausalAttention function causal_attention = CausalAttention( d_model, n_heads=n_heads, mode=mode )
# Create feed-forward block (list) with two dense layers with dropout and input normalized feed_forward = [ tl.LayerNorm(), tl.Dense(d_ff), ff_activation(), # Generally ReLU tl.Dropout(rate=dropout, mode=mode), tl.Dense(d_model), tl.Dropout(rate=dropout,mode=mode) ]
# Add list of two Residual blocks: the attention with normalization and dropout and feed-forward blocks return [ tl.Residual( tl.LayerNorm(), causal_attention, tl.Dropout(rate=dropout, mode=mode) ), tl.Residual( feed_forward ), ]
defTransformerLM(vocab_size=33300, d_model=512, d_ff=2048, n_layers=6, n_heads=8, dropout=0.1, max_len=4096, mode='train', ff_activation=tl.Relu): """Returns a Transformer language model. The input to the model is a tensor of tokens. (This model uses only the decoder part of the overall Transformer.) Args: vocab_size (int): vocab size. d_model (int): depth of embedding. d_ff (int): depth of feed-forward layer. n_layers (int): number of decoder layers. n_heads (int): number of attention heads. dropout (float): dropout rate (how much to drop out). max_len (int): maximum symbol length for positional encoding. mode (str): 'train', 'eval' or 'predict', predict mode is for fast inference. ff_activation (function): the non-linearity in feed-forward layer. Returns: trax.layers.combinators.Serial: A Transformer language model as a layer that maps from a tensor of tokens to activations over a vocab set. """ # Embedding inputs and positional encoder positional_encoder = [ tl.Embedding(vocab_size, d_model), tl.Dropout(rate=dropout, mode=mode), tl.PositionalEncoding(max_len=max_len, mode=mode)]
# Create stack (list) of decoder blocks with n_layers with necessary parameters decoder_blocks = [ DecoderBlock(d_model, d_ff, n_heads, dropout, mode, ff_activation) for _ in range(n_layers)]
deftraining_loop(TransformerLM, train_gen, eval_gen, output_dir = "~/model"): ''' Input: TransformerLM (trax.layers.combinators.Serial): The model you are building. train_gen (generator): Training stream of data. eval_gen (generator): Evaluation stream of data. output_dir (str): folder to save your file. Returns: trax.supervised.training.Loop: Training loop. ''' output_dir = os.path.expanduser(output_dir) # trainer is an object lr_schedule = trax.lr.warmup_and_rsqrt_decay(n_warmup_steps=1000, max_value=0.01)
defnext_symbol(cur_output_tokens, model): """Returns the next symbol for a given sentence. Args: cur_output_tokens (list): tokenized sentence with EOS and PAD tokens at the end. model (trax.layers.combinators.Serial): The transformer model. Returns: int: tokenized symbol. """ # current output tokens length token_length = len(cur_output_tokens)
defgreedy_decode(input_sentence, model): """Greedy decode function. Args: input_sentence (string): a sentence or article. model (trax.layers.combinators.Serial): Transformer model. Returns: string: summary of the input. """ # Use tokenize() cur_output_tokens = tokenize(input_sentence) + [0] generated_output = [] cur_output = 0 EOS = 1 while cur_output != EOS: # Get next symbol cur_output = next_symbol(cur_output_tokens, model) # Append next symbol to original sentence cur_output_tokens.append(cur_output) # Append next symbol to generated sentence generated_output.append(cur_output) print(detokenize(generated_output)) return detokenize(generated_output)
测试:
1 2 3 4 5
# Test it out on a sentence! test_sentence = "It padded_with_batch was a sunny day when I went to the market to buy some flowers. But I only found roses, not tulips." print(wrapper.fill(test_sentence), '\n') print(greedy_decode(test_sentence, model)) # Strange outout but auto_grader doesnt count it uncorrect
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
It padded_with_batch was a sunny day when I went to the market to buy some flowers. But I only found roses, not tulips.
: : I : I just : I just found : I just found ros : I just found roses : I just found roses, : I just found roses, not : I just found roses, not tu : I just found roses, not tulips : I just found roses, not tulips : I just found roses, not tulips. : I just found roses, not tulips.<EOS> : I just found roses, not tulips.<EOS>